
Αρχική σελίδα Παράλληλης Επεξεργασίας
English version (Αγγλική έκδοση)
Parallel PIC
Η σελίδα αυτή περιγράφει την μηχανή ParallelPIC έκδοση 2.0. Η πρώτη έκδοση της μηχανής αυτής συμμετείχε σε έναν διαγωνισμό του περιοδικού CircuitCellar.
Υπολογιστής Παράλληλης Επεξεργασίας
1. Εισαγωγή
Ο στόχος της παρούσας εργασίας είναι να κατασκευαστεί ένα υπολογιστής που εκμεταλλεύεται τη συνδυασμένη υπολογιστική ισχύ πολλών μικροελεγκτών (MCUs). Όλοι οι μικροελεγκτές συνεργάζονται για να λύσουν ένα πρόβλημα. Ο υπολογιστής ονομάζεται "παράλληλος υπολογιστής" και οι αλγόριθμοι που εκτελούνται σε αυτόν ονομάζονται "παράλληλοι αλγόριθμοι".
Ο υπολογιστής μπορεί να χρησιμοποιηθεί ως ένα εκπαιδευτικό σύστημα που μπορεί να βοηθήσει την ανάπτυξη, την κατανόηση και την βελτιστοποίηση πολλών παράλληλων αλγορίθμων. Ακόμη μπορεί να χρησιμοποιηθεί για την επίτευξη υψηλών επιδόσεων σε περιπτώσεις όπως η Ψηφιακή Επεξεργασία Σήματος.
Ο παράλληλος υπολογιστής μπορεί να κατασκευαστεί σχετικά εύκολα από έναν ερασιτέχνη ηλεκτρονικό. Ωστόσο η αποδοτική χρήση του είναι πιο δύσκολη και απαιτεί μεγάλη προσπάθεια καθώς η ανάπτυξη και η υλοποίηση παράλληλων αλγορίθμων είναι μια δύσκολη δουλειά.
Στο επόμενο τμήμα (2) γίνεται μια εισαγωγή στους παράλληλους υπολογιστές. Στο τμήμα 3 περιγράφεται το υλικό, ενώ στο τμήμα 4 περιγράφεται το λογισμικό (τόσο το λογισμικό που εκτελείται στο PC όσο και το firmware που βρίσκεται μέσα στον παράλληλο υπολογιστή. Στο τμήμα 5 παρουσιάζονται αναλυτικά κάποιοι παράλληλοι αλγόριθμοι που εκτελούνται στον παράλληλο υπολογιστή. Τέλος στο τμήμα 6 δίνονται τα συμπεράσματα της εργασίας.
Ο πηγαίος κώδικας για τα παραδείγματα βρίσκεται στο συμπιεσμένο αρχείο "ParallelPIC_examples.zip". Ο πηγαίος κώδικας για το λογισμικό που εκτελείται στο PC βρίσκεται στο αρχείο "ParallelPIC_PCcode_V2.zip" και ο πηγαίος κώδικας (και τα hex αρχεία) του firmware βρίσκονται στο αρχείο "ParallelPIC_firmwareV2.zip".
2. Εισαγωγή στην Παράλληλη Επεξεργασία
Ο παράλληλος υπολογιστής που παρουσιάζεται ανήκει στην κατηγορία των “Single Instruction Multiple Data” (SIMD) που σημαίνει ότι όλες οι μονάδες επεξεργασίας εκτελούν το ίδιο πρόγραμμα, αλλά κάθε μονάδα χειρίζεται διαφορετικό σύνολο δεδομένων. (Στην πραγματικότητα, υπάρχουν περιπτώσεις όπου μόνο ένα υποσύνολο των μονάδων επεξεργασίας εκτελούν πραγματικό κώδικα ενώ οι υπόλοιπες περιμένουν. Αυτό εμπεριέχεται σε ορισμένους αλγόριθμους και παρουσιάζεται λεπτομερώς παρακάτω). Οι μονάδες επεξεργασίας επικοινωνούν μεταξύ τους για την ανταλλαγή δεδομένων. Έτσι δημιουργείται ένα "δίκτυο" ανταλλαγής δεδομένων. Η τοπολογία του δικτύου αυτού επηρεάζει τη σχεδίαση των αλγορίθμων που εκτελούνται στην παράλληλη μηχανή.
Η παράλληλη μηχανή αναπαρίσταται γραφικά με τη χρήση κύκλων για τις μονάδες επεξεργασίας και ακμών για την μεταξύ τους επικοινωνία. (η επικοινωνία μεταξύ δύο μονάδων επεξεργασίας μπορεί να είναι μονόδρομη ή αμφίδρομη). Το παρακάτω διάγραμμα δείχνει δύο κοινές τοπολογίες:
Διάγραμμα 1: Τοπολογία μήτρας και δένδρου.
Περισσότερες τοπολογίες περιγράφονται στη σελίδα της θεωρίας.
Ακολουθεί ένα παράδειγμα της χρήσης του δένδρου: Έστω ότι το πρόβλημα είναι να βρεθεί το μέγιστο μεταξύ 8 αριθμών. Χρησιμοποιούμε τη δομή του δυαδικού δένδρου που παρουσιάζεται στο προηγούμενο διάγραμμα. Οι MCUs 1,2,3,4 ονομάζονται "φύλλα". Η MCU 7 ονομάζεται "ρίζα". Τα φύλλα κρατούν τα δεδομένα εισόδου. Κάθε MCU συγκρίνει τις δύο (2) τιμές εισόδου, βρίσκει την μεγαλύτερη και την δίνει στην μονάδα που είναι πιο πάνω στην ιεραρχία του δένδρου. Για παράδειγμα, η MCU 5 παίρνει δύο τιμές από τις MCUs 1 και 2 και περνάει το μέγιστο στην MCU 7. Αυτός ο αλγόριθμος (διάβασε - σύγκρινε - γράψε) εκτελείται επαναληπτικά. Με τον τρόπο αυτό η ρίζα (MCU 7) θα έχει τον μέγιστο από τους 8 αριθμούς εισόδου μετά από τρεις (3) επαναλήψεις του κύκλου: Στον πρώτο κύκλο οι MCUs 1,2,3,4 θα στείλουν τα σωστά αποτελέσματα στις πιο πάνω MCUs, στον δεύτερο κύκλο οι MCUs 5, 6 θα στείλουν σωστά αποτελέσματα, και τελικά στον τρίτο κύκλο η MCU 7 θα έχει το μέγιστο.
Έχουν αναπτυχθεί πολλοί αλγόριθμοι για την επίλυση προβλημάτων σε τέτοιου τύπου παράλληλες μηχανές, καλύπτοντας πολλές περιοχές από στοιχειώδεις λειτουργίες όπως η απαρίθμηση μέχρι σύνθετες λειτουργίες όπως ο μετασχηματισμός Fourier, βελτιστοποίηση και λοιπά.
Το δίκτυο διασύνδεσης παίζει σημαντικό ρόλο στην αποδοτικότητα του αλγορίθμου. Το πιο ισχυρό δίκτυο είναι αυτό όπου κάθε MCU επικοινωνεί κατευθείαν με κάθε άλλη MCU. Ωστόσο αυτό δεν είναι ένα πρακτικά υλοποιήσιμο δίκτυο και οι αλγόριθμοι επικεντρώνονται σε απλούστερα δίκτυα. Μια κρίσιμη παράμετρος είναι ο αριθμός των συνδέσεων για κάθε MCU. Στην τοπολογία μήτρας κάθε MCU συνδέεται με τέσσερις (4) το πολύ άλλες MCUs. Στο δυαδικό δένδρο χρειάζονται τρεις (3) γραμμές επικοινωνίας και κάθε MCU. Ένα πολύ ισχυρό δίκτυο είναι ο υπερκύβος που απαιτεί (n) συνδέσεις για κάθε MCU όταν υπάρχουν 2n MCUs (για παράδειγμα σε έναν υπερκύβο με 64 MCUs κάθε MCU επικοινωνεί με 8 άλλες MCUs).
Περισσότερες πληροφορίες σχετικά με την παράλληλη επεξεργασία υπάρχουν σε αρκετά βιβλία, αν και τα περισσότερα από αυτά είναι γραμμένα για προπτυχιακούς και μεταπτυχιακούς φοιτητές. Δύο από αυτά τα βιβλία είναι:
F. Thomson Leighton, “Introduction to parallel algorithms and architectures: arrays, trees, hypercubes,” Morgan Kaufmann Publishers Inc., San Francisco, CA, 1991.
P. Chaudhuri, “Parallel Algorithms – Design and Analysis,” Prentice Hall, 1992.
3. Περιγραφή υλικού
Ο παράλληλος υπολογιστής αποτελείται από έναν αριθμό από μικροελεγκτές (MCU). Κάθε MCU μπορεί να επικοινωνεί με έναν ή περισσότερους άλλους μικροελεγκτές μέσω μιας σειριακής επικοινωνίας (στην παρούσα μορφή του υπολογιστή κάθε MCU μπορεί να επικοινωνεί με δώδεκα (12) το πολύ άλλους μικροελεγκτές). Ο χρήστης τοποθετεί τα καλώδια που υλοποιούν την επικοινωνία μεταξύ των μικροελεγκτών.
Όλοι οι μικροελεγκτές εκτελούν κώδικα από την εσωτερική μνήμη flash που έχουν. Οι μικροελεγκτές φορτώνονται με τον ίδιο κώδικα (αν και αυτό δεν είναι αληθές για όλες τις περιπτώσεις όπως έχει ήδη αναφερθεί πιο πάνω). Ένα βασικό χαρακτηριστικό για την υλοποίηση της παράλληλης μηχανής είναι να μπορούν όλοι οι μικροελεγκτές να εκτελούν το πρόγραμμά τους σε πλήρη συγχρονισμό μεταξύ τους. Αυτό επιτυγχάνεται με τη χρήση ενός εξωτερικού ρολογιού, και με τον εξαναγκασμό όλων των μικροελεγκτών να ξεκινήσουν την εκτέλεση του προγράμματος την ίδια ακριβώς χρονική στιγμή. Και τα δύο αυτά στοιχεία είναι επιτεύξιμα με τους μικροελεγκτές της οικογένειας PIC24FJxx.
Οι μικροελεγκτές χρησιμοποιούν την εσωτερική μονάδα UART για την σειριακή επικοινωνία μεταξύ τους. Αυτό εισάγει μια σχετικά μεγάλη καθυστέρηση στην εκτέλεση του αλγορίθμου σε σχέση με κάποια παράλληλη επικοινωνία, αλλά το όφελος είναι ότι αυξάνει την διασυνδεσιμότητα μεταξύ των μικροελεγκτών και έτσι γίνεται εφικτή η υλοποίηση δικτύων όπως ο υπερκύβος.
Στην παρακάτω εικόνα παρουσιάζεται το γενικό διάγραμμα του παράλληλου υπολογιστή (παρατηρήστε ότι το δίκτυο επικοινωνίας δεν φαίνεται καθώς σχηματίζεται από τον χρήστη!)

Διάγραμμα 2: Γενικό διάγραμμα του παράλληλου υπολογιστή
Ο παράλληλος υπολογιστής αποτελείται από μικροελεγκτές, ένα ρολόι με ένα κύκλωμα ελέγχου, και έναν μικροελεγκτή "ελέγχου" που παρέχει την σειριακή επικοινωνία με έναν προσωπικό υπολογιστή (PC).
Το κύκλωμα του ρολογιού και το κύκλωμα ελέγχου αποτελούνται από έναν κρυσταλλικό ταλαντωτή, και ένα κύκλωμα με flip-flop που επιτρέπει ή όχι την μεταφορά του σήματος του ταλαντωτή στους μικροελεγκτές. Υπάρχουν δύο λόγοι για την ύπαρξη αυτού του κυκλώματος: Κατ' αρχήν όλοι οι μικροελεγκτές θα πρέπει να βρίσκονται σε πλήρη συγχρονισμό για την σωστή εκτέλεση του προγράμματος. Αυτό γίνεται εφικτό με τη χρήση του σήματος reset (MCLR) και της εισόδου χρονισμού των μικροελεγκτών. Η διαδικασία είναι η εξής: Όλοι οι μικροελεγκτές βρίσκονται αρχικά σε κατάσταση RESET (MCLR=0) και το ρολόι είναι απενεργοποιημένο. Μετά οι μικροελεγκτές βγαίνουν από την κατάσταση reset (MCLR=1) (αλλά ακόμα δεν εκτελούν κώδικα καθώς δεν έχουν σήμα χρονισμού!). Μετά το ρολόι ενεργοποιείται και όλοι οι μικροελεγκτές εκτελούν κώδικα σε πλήρη συγχρονισμό μεταξύ τους! Ο δεύτερος λόγος για τη χρήση ενός διακόπτη enable/disable είναι για να δώσει στο χρήστη τη δυνατότητα να "παγώσει" την εκτέλεση του προγράμματος όποια χρονική στιγμή θέλει για λόγους αποσφαλμάτωσης ή για εκπαιδευτικούς λόγους
Για την επικοινωνία με το PC χρησιμοποιείται ένας άλλος μικροελεγκτής PIC24FJ16GA002 ο οποίος παίρνει εντολές από μια σειριακή θύρα (RS232) και επικοινωνεί με κάθε MCU μέσω των σημάτων MCLR, PGC και PGD. Στο PC πρέπει να εκτελείται ένα ειδικό πρόγραμμα που δημιουργεί την διεπαφή χρήστη - παράλληλης μηχανής. Τα σήματα MCLR και PGC είναι κοινά για όλες τις MCU. Κάθε MCU επιλέγεται ανεξάρτητα από τις υπόλοιπες με τη χρήση ανεξάρτητων γραμμών PGD. Ο βασικός ρόλος του μικροελεγκτή "ελέγχου" είναι να ανιχνεύει ποιοι μικροελεγκτές υπάρχουν και να τους "φορτώνει" με το κατάλληλο πρόγραμμα.
Το πλήρες σχηματικό διάγραμμα δίνεται στην επόμενη εικόνα:

Εικόνα 3: Πλήρες σχηματικό διάγραμμα του παράλληλου υπολογιστή με 8 MCUs.
Κάθε MCU έχει έναν συνδετήρα των 12 επαφών (J1) για την επικοινωνία με τις άλλες MCUs. Η επικοινωνία γίνεται με τη χρήση των UARTs. Ο μηχανισμός Peripheral Pin Select των συγκεκριμένων μικροελεγκτών χρησιμοποιείται για την αντιστοίχηση των UARTs με τους επιθυμητούς ακροδέκτες.
Κάθε MCU έχει έναν συδετήρα των 4 επαφών (J2) για βοηθητική Είσοδο/Έξοδο.
Κάθε MCU επικοινωνεί με τον μικροελεγκτή ελέγχου μέσω των ακροδεκτών MCLR, PGC, PGD.
Όλες οι MCUs μοιράζονται τα ίδια σήματα RESET και CLOCK. Το σήμα χρονισμού πρέπει να διαδίδεται με ισόποση καθυστέρηση μεταξύ των μικροελεγκτών, έτσι ώστε όλοι οι μικροελεγκτές να είναι πλήρως συγχρονισμένοι μεταξύ τους.
Γύρω από τις πύλες U9B, U9D, U9E χτίζεται ένας κρυσταλλικός ταλαντωτής. Δύο από τα latches που βρίσκονται μέσα στο U10 χρησιμοποιούνται σαν ένα master-slave flip-flop το οποίο συγχρονίζει το σήμα clock enable/disable με την έξοδο του κρυσταλλικού ταλαντωτή. Οι πύλες του U11 διανέμουν το σήμα χρονισμού στους μικροελεγκτές (ο μικροελεγκτής ελέγχου χρησιμοποιεί το εσωτερικό ρολόι των 8ΜΗΖ). Τα ολοκληρωμένα U9, U10 και U11 είναι TTL και εργάζονται με 5V. Οι πύλες μέσα στο U11 είναι τύπου ανοιχτού συλλέκτη για να κάνουν μετατροπή σημάτων στα 3V που εργάζονται οι MCUs.
Η επικοινωνία με το PC γίνεται με τον μικροελεγκτή U14. Η σειριακή πόρτα του μικροελεγκτή δεν παράγει τα σωστά επίπεδα για μια σύνδεση RS232, και άρα πρέπει να χρησιμοποιηθεί ένας μετατροπέας σταθμών. Προτείνω τον μετατροπέα σταθμών που περιγράφεται σε άλλη σελίδα αυτού του ιστότοπου. (Προσέξτε ότι το U14 τροφοδοτείται με 3V και όχι με 5V, άρα το MAX232 δεν είναι καλή επιλογή.) Ο μικροελεγκτής ελέγχου μπορεί να προγραμματιστεί "in circuit". Ο συνδετήρας P17 χρησιμοποιείται για το λόγο αυτό. Κάθε "In-circuit programmer" μπορεί να χρησιμοποιηθεί. Το κύκλωμα έχει ελεγχθεί με τον προγραμματιστή που περιγράφεται σε άλλη σελίδα αυτού του ιστότοπου. Το "firmware" που εκτελείται στον μικροελεγκτή ελέγχου έχει γραφεί σε assembly και έχει μεταγλωττιστεί με το MPLAB 8.10. Ο πηγαίος κώδικας και το αρχείο hex είναι διαθέσιμα για download.
Οι Configuration Words κάθε μικροελεγκτή πρέπει να τεθούν για JTAG disable (καθώς οι αντίστοιχοι ακροδέκτες χρησιμοποιούνται για την επικοινωνία των μικροελεγκτών), External clock, Oscillator output disabled, WDT disabled, IOLOCK can change.
Τα 3V που απαιτούνται από τους μικροελεγκτές παράγονται από την τροφοδοσία των 5V χρησιμοποιώντας τρεις (3) διόδους σε ορθή πόλωση. Η πραγματική τιμή της τάσης μπορεί να είναι μικρότερη (περίπου 2.8V με πλήρες φορτίο) αλλά είναι μέσα στην περιοχή τάσεων που είναι ανεκτές από τους μικροελεγκτές (2.2V – 3.6V). Όλοι οι μικροελεγκτές έχουν ενεργοποιημένο τον εσωτερικό σταθεροποιητή.
Στην επόμενη φωτογραφία φαίνεται ο πρωτότυπος παράλληλος υπολογιστής με 8 MCUs:

Φωτογραφία 1: Το πρωτότυπο του παράλληλου υπολογιστή με 8 MCUs.
4. Λογισμικό υποστήριξης
4.1) Λογισμικό για το PC
Τα προγράμματα που εκτελούνται στον παράλληλο υπολογιστή έχουν γραφεί και μεταγλωττιστεί με τη χρήση του MPLAB IDE 8.10. Τα προγράμματα αυτά είναι γραμμένα σε assembly ώστε να διασφαλίζεται ο συγχρονισμός των μικροελεγκτών.
Ο κώδικας "κατεβαίνει" στους μικροελεγκτές με τη χρήση ενός ειδικού προγράμματος που έχει αναπτυχθεί για το λόγο αυτό. Το πρόγραμμα επικοινωνεί με την μηχανή ParallelPIC μέσω της σειριακής θύρας COM1. Το λογισμικό έχει αναπτυχθεί με την Visual Basic 2005 Express Edition (διατίθεται ελεύθερα από την Microsoft). Προτείνω να δημιουργηθεί ένα νέο project και να αντικατασταθούν τα αρχεία "form1.vb" και "form1.designer.vb" με τα αντίστοιχα αρχεία που διατίθενται από τον ιστότοπο αυτό.
Στην επόμενη εικόνα φαίνεται ένα στιγμιότυπο του User’s Interface:
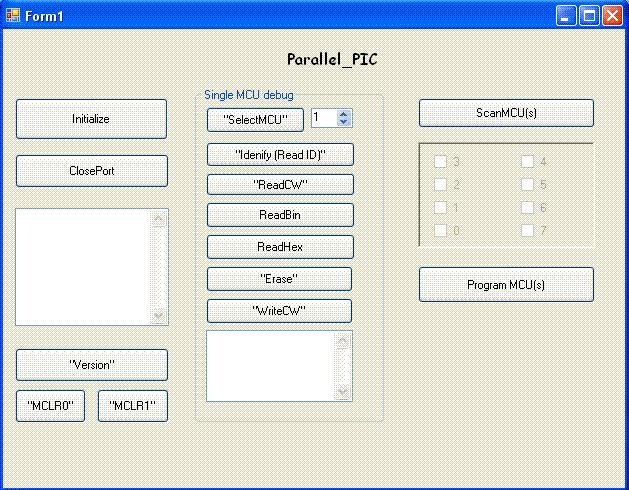
Εικόνα 4: User’s interface από το λογισμικό προγραμματισμού.
Το κουμπί "Initialize" χρησιμοποιείται για την αρχικοποίηση του προγράμματος (κάτι που γίνεται και με το άνοιγμα του προγράμματος).
Το κουμπί "ClosePort" χρησιμοποιείται για να τερματίσει την επικοινωνία μέσω της σειριακής πόρτας (κάτι που γίνεται και με το κλείσιμο του προγράμματος).
Το κουμπί "Version" χρησιμοποιείται για να στείλει την ομώνυμη εντολή στον Parallel_PIC. Το αποτέλεσμα εμφανίζεται στο πλαίσιο που βρίσκεται πάνω από το κουμπί αυτό.
Το κουμπί "MLCR0" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Paralel_PIC. Οι μονάδες επεξεργασίας μπαίνουν όλες σε κατάσταση RESET.
Το κουμπί "MLCR1" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Paralel_PIC. Οι μονάδες επεξεργασίας μπαίνουν όλες σε κατάσταση κανονικής εκτέλεσης προγράμματος
Στη μεσαία στήλη υπάρχουν κουμπιά για τον έλεγχο μίας MCU. Αυτά χρησιμοποιούνται κυρίως για το debuging και για την ανίχνευση προβλημάτων σε MCUs, και όχι στην κανονική λειτουργία!
Το κουμπί "Select MCU" χρησιμοποιείται σε συνδιασμό με το πλαίσιο στα δεξιά του για την επιλογή της MCU που θα χρησιμοποιηθεί σε άλλες λειτουργίες των κουμπιών αυτής της στήλης. Στέλνει την αντίστοιχη εντολή στον Parallel_PIC.
Το κουμπί "Idenify (Read ID)" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Parallel_PIC. Το αποτέλεσμα της εντολής είναι ο αριθμός ID του επιλεγμένου μικροελεγκτή που εμφανίζεται στο κάτω-κάτω πλαίσιο της στήλης αυτής.
Το κουμπί "ReadCW" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Parallel_PIC. Το αποτέλεσμα της εντολής είναι οι δύο λέξεις του CodeWord του επιλεγμένου μικροελεγκτή που εμφανίζεται στο κάτω-κάτω πλαίσιο της στήλης αυτής.
Το κουμπί "ReadBin" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Parallel_PIC. Το αποτέλεσμα της εντολής είναι να στείλει ο Parallel_PIC όλα τα δεδομένα της μνήμης Flash του επιλεγμένου μικροελεγκτή. Η μετάδοση των δεδομένων γίνεται με δυαδικό τρόπο. Τα δεδομένα μετατρέπονται σε δεκαεξαδικά ASCII και αποθηκεύονται στο αρχείο ".\FlashDump.txt".
Το κουμπί "ReadHex" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Parallel_PIC. Το αποτέλεσμα της εντολής είναι να στείλει ο Parallel_PIC όλα τα δεδομένα της μνήμης Flash του επιλεγμένου μικροελεγκτή. Η μετάδοση των δεδομένων γίνεται με χαρακτήρες ASCII. Τα δεδομένα αποθηκεύονται στο αρχείο ".\FlashDumpHex.txt".
Το κουμπί "Erase" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Parallel_PIC. Το αποτέλεσμα της εντολής είναι να διαγραφούν όλα τα δεδομένα από τη μνήμη Flash του επιλεγμένου μικροελεγκτή.
Το κουμπί "WriteCW" χρησιμοποιείται για να στείλει την αντίστοιχη εντολή στον Parallel_PIC. Το αποτέλεσμα της εντολής είναι να γραφτούν ξανά οι δύο λέξεις του CodeWord του επιλεγμένου μικροελεγκτή (Σημείωση: το firmware δεν δίνει ακόμη την δυνατότητα να καθορίζει ο χρήστης την τιμή των λέξεων CW. Οι τιμές αυτές είναι προκαθορισμένες από το firmware.)
Το κουμπί "ScanMCU(s)" χρησιμοποιείται για να ανιχνευθούν οι MCUs και να φανούν πόσες από αυτές είναι διαθέσιμες.
Τα check-boxes χρησιμοποιούνται για να επιλεγούν οι MCUs που θα προγραμματιστούν.
Το κουμπί "Program MCU(s)" χρησιμοποιείται για να επιλεγεί ένα αρχείο hex και να φορτωθεί σε όλες τις MCU(s) που έχουν επιλεγεί.
4.2) Firmware
Το firmware που εκτελείται στον μικροελεγκτή ελέγχου χρησιμοποιεί την σειριακή θύρα για την επικοινωνία με το PC. Το μεγαλύτερο τμήμα της επικοινωνίας γίνεται με ASCII εντολές και τις αποκρίσεις τους. Ο μικροελεγκτής ελέγχου εκτελεί έναν ατέρμονο βρόγχο όπου περιμένει εντολή από το PC. Όταν λαμβάνει μια εντολή, ο μικροελεγκτής την εκτελεί και επιστρέφει στον ατέρμονα βρόγχο. Αν και όλες οι εντολές είναι σε ASCII μορφή, τα δεδομένα που ανταλλάσσονται είναι σε ορισμένες περιπτώσεις σε δυαδική μορφή. Αυτό σημαίνει ότι το λογισμικό που εκτελείται στο PC και συνεργάζεται με το firmware δεν μπορεί να είναι πάντα ένα απλό πρόγραμμα ASCII τερματικού.
ΟΙ εντολές που υλοποιούνται περιλαμβάνουν ανίχνευση MCU, επιλογή ενός διαθέσιμου μικροελεγκτή, ανάγνωση και εγγραφή της μνήμης flash, διάβασμα και γράψιμο των Configuration Words του επιλεγμένου μικροελεγκτή, και πλήρης διαγραφή του επιλεγμένου μικροελεγκτή.
Υπάρχει ένα μικρό πρόβλημα με τη χρήση του λογισμικού αυτού: Η μνήμη flash διαγράφεται εντελώς σε κάθε κύκλο προγραμματισμού. Έτσι οι configuration words πρέπει να επαναπρογραμματίζονται σε κάθε κύκλο προγραμματισμού. Με τον τρόπο αυτό όμως οι configuration words μπαίνουν πρώτα στην αρχική κατάσταση και μετά μπαίνουν σε κατάσταση για εξωτερικό σήμα χρονισμού. Η διαδικασία αυτή "μπερδεύει" λίγο τους μικροελεγκτές που θα πρέπει να ¨τρέξουν¨ λίγο με το εξωτερικό ρολόι και μετά λειτουργούν όπως αναμένεται (δηλαδή ταυτόχρονη εκκίνηση και δυνατότητα για πάγωμα του ρολογιού).
5. Παράλληλος προγραμματισμός
Στο τμήμα αυτό παρουσιάζονται κάποιοι παράλληλοι αλγόριθμοι. Ο κώδικας που υλοποιεί κάθε αλγόριθμο δεν είναι βελτιστοποιημένος για ταχύτητα εκτέλεσης καθώς ο βασικός του ρόλος είναι εκπαιδευτικός. Μόνο στο τελευταίο παράδειγμα συζητείται ένας αλγόριθμος βελτιστοποιημένος για ταχύτητα.
Όλοι οι αλγόριθμοι χρησιμοποιούν έναν κοινό κώδικα για την αρχικοποίηση των UART. Οι UARTs λειτουργούν στον μέγιστο ρυθμό (baud rate = Fosc / 8). Δεν χρησιμοποιούνται σήματα διακοπών. Τα σήματα εισόδου και εξόδου των UART αντιστοιχούνται σε ακροδέκτες RPx ανάλογα με τον κάθε αλγόριθμο και την τοπολογία δικτύου. Αυτή η αντιστοίχηση μπορεί να αλλάζει δυναμικά κατά την διάρκεια εκτέλεσης του προγράμματος.
5.1 Linear array – Έλεγχος με απλή διάδοση δεδομένων.
Το δίκτυο διασύνδεσης για τον αλγόριθμο αυτό είναι ένα linear array σε μία (1) διάσταση. Αυτό σημαίνει ότι όλοι οι μικροελεγκτές θεωρούνται ότι σχηματίζουν μία γραμμή. Κάθε μικροελεγκτής επικοινωνεί με τον προηγούμενο και τον επόμενο εκτός από τον πρώτο που δεν έχει προηγούμενο και τον τελευταίο που δεν έχει επόμενο.
Η επόμενη εικόνα δείχνει αυτήν την τοπολογία:

Εικόνα 5: Ένα Linear array.
Τα βέλη δηλώνουν ότι οι μικροελεγκτές στέλνουν δεδομένα προς τα δεξιά και λαμβάνουν δεδομένα από αριστερά.
Το "πρόβλημα" είναι να μεταφερθούν (ή "δρομολογηθούν") τα δεδομένα από τον αριστερό μικροελεγκτή (1) προς τον δεξιότερο μικροελεγκτή (8).
Ακολουθεί η "λύση":
- Κάθε MCU έχει μια μεταβλητή που κρατάει την τιμή που πρέπει να διαδοθεί.
- Κάθε μία από τις εσωτερικές MCUs (2 με 7) στέλνει την τιμή της μεταβλητής της στην MCU προς τα δεξιά και λαμβάνει μια νέα τιμή από την MCU από αριστερά της.
- Ο αριστερότερος μικροελεγκτής διαβάζει νέα τιμή από την PortA αντί να τη διαβάζει από άλλον μικροελεγκτή. Για πρακτικούς λόγους αυτή η τιμή έχει εύρος μόνο 2-bit (PortA0, PortA1).
- Η δεξιότερη MCU γράφει την τιμή της μεταβλητής της στην PortA(3,4) αντί να τη στέλνει σε άλλον μικροελεγκτή.
Στον επόμενο πίνακα δίνεται ο κώδικας για τις τρεις αυτές περιπτώσεις.
;Left loop: ;============ ; read value MOV PORTA,W1 AND W1,W2,W1 ;============= ; send value MOV W1,U1TXREG ;============= ; Wait MOV #100,W3 loopW: NOP DEC W3,W3 BRA NZ,loopW ;============= ; receive value MOV U1RXREG,W1 ;============= ; NOP NOP NOP ;============= BRA loop |
;Middle loop: ;============ ; NOP NOP ;============= ; send value MOV W1,U1TXREG ;============= ; Wait MOV #100,W3 loopW: NOP DEC W3,W3 BRA NZ,loopW ;============= ; receive value MOV U1RXREG,W1 ;============= ; NOP NOP NOP ;============= BRA loop |
;Right loop: ;============ ; NOP NOP ;============= ; send value MOV W1,U1TXREG ;============= ; Wait MOV #100,W3 loopW: NOP DEC W3,W3 BRA NZ,loopW ;============= ; receive value MOV U1RXREG,W1 ;============= ; Write value AND W1,W2,W1 SL W1,#3,W1 MOV W1,PORTA ;============= BRA loop |
Πίνακας 1: Ο κώδικας για την απλή μεταφορά δεδομένων σε linear array.
Μεταξύ μετάδοσης και λήψης δεδομένων εισάγεται μια καθυστέρηση που εξασφαλίζει τη σωστή επικοινωνία μεταξύ των μικροελεγκτών. Η καθυστέρηση δεν αντιστοιχεί ακριβώς στο πλήθος των κύκλων που απαιτούνται, αλλά δίνει αρκετό χρόνο για την αποστολή και τη λήψη μιας λέξης των 8-bit.
Όλοι οι μικροελεγκτές έχουν ακριβώς τον ίδιο κώδικα αρχικοποίησης.
Σε αυτόν τον αλγόριθμο κάθε μικροελεγκτής χρησιμοποιεί ένα (1) UART. Ο δέκτης του UART αντιστοιχίζεται στον ακροδέκτη RP14, ενώ ο πομπός αντιστοιχίζεται στο RP15. Το δίκτυο διασύνδεσης δημιουργείται συνδέοντας το RP15 της MCU με αριθμό (k) με το RP14 της MCU με αριθμό (k+1).
Οι εντολές NOP εισάγονται για να διατηρηθεί ο συγχρονισμός όλων των MCUs.
Τα πρώτα λίγα δεδομένα που βγαίνουν από την PortA της MCU 8 δεν έχουν νόημα, καθώς αντιστοιχούν σε τιμές των μεταβλητών μέσα στις MCUs. Ο βρόγχος θα πρέπει να εκτελεστεί επτά; (7) φορές για να βγουν σωστά αποτελέσματα. Κάθε αλλαγή στα δεδομένα εισόδου θα μεταφερθεί στην έξοδο σε επτά (7) εκτελέσεις του βρόγχου.
Ένας απλός έλεγχος για τη σωστή λειτουργία του "παγώματος" του ρολογιού είναι να σταματήσουμε το ρολόι, να αλλάξουμε την είσοδο και να επιβεβαιώσουμε ότι η έξοδος δεν αλλάζει. Όταν το ρολόι ενεργοποιηθεί ξανά, η έξοδος θα πρέπει να αλλάξει (η διαδικασία εκκίνησης εκτέλεσης προγραμμάτων στον παράλληλο υπολογιστή περιγράφεται στο τμήμα 2).
Η επόμενη φωτογραφία δείχνει τον παράλληλο υπολογιστή (την έκδοση 1.0) με την απαραίτητη τοπολογία και μια απλή κάρτα ελέγχου με jumpers για είσοδο και leds για έξοδο.

Φωτογραφία 2: Ο παράλληλος υπολογιστής (V1.0) συνδεδεμένος ως linear array.
Τα απαραίτητα αρχεία βρίσκονται στον φάκελο “LinearArray_route”. Ο πηγαίος κώδικας σε assembly που που βρίσκεται στο αρχείο “LinearArray_route.s” αναφέρεται στην αριστερότερη MCU. Όταν δημιουργηθεί το project και γίνει build, το αρχείο hex που θα παραχθεί θα πρέπει να μετονομαστεί με το χέρι (αυτό έχει ήδη γίνει για το παράδειγμα αυτό και το αρχείο έχει μετονομαστεί σε “LinearArray_route_L.hex”). Μετά ο χρήστης θα πρέπει να αντικαταστήσει το κώδικα που αναφέρεται μόνο στην αριστερότερη MCU με τον κώδικα που αναφέρεται στις μεσαίες MCUs (μια απλή λειτουργία αντιγραφής - επικόλλησης) και να κάνει ξανά build. Το νέο αρχείο hex μετονομάστηκε σε “LineArray_route_M.hex”. Η διαδικασία επαναλαμβάνεται μια φορά ακόμα για την δεξιότερη MCU (αρχείο “LinearArray_route_R.hex”). Τώρα ο χρήστης μπορεί να χρησιμοποιήσει τον λογισμικό του PC για να αποθηκεύσει τον κώδικα στους μικροελεγκτές. Στο τμήμα 5.3 παρουσιάζεται μια άλλη μέθοδος με χρήση του conditional assembling.
5.2 Δυαδικό δένδρο – Άθροισμα μικρών ακεραίων.
Το δίκτυο διασύνδεσης για αυτόν τον αλγόριθμο είναι ένα δυαδικό δένδρο με 4 φύλλα.
Η παρακάτω εικόνα δείχνει αυτήν την τοπολογία:

Εικόνα 6: Δυαδικό δένδρο με 4 φύλλα.
Τα βέλη δείχνουν την κατεύθυνση της μετάδοσης δεδομένων. Οι MCUs 1,2,3,4 καλούνται ¨φύλλα¨, η MCU 5 είναι ο "μπαμπάς" των MCUs 1,2, και άρα οι MCUs 1,2 είναι τα "παιδιά" της MCU 5. Αντίστοιχη ονομασία ισχύει για τις άλλες MCUs. Η MCU 7 καλείται ακόμη και "ρίζα" του δένδρου.
Το "πρόβλημα" είναι να αθροιστούν όλα τα δεδομένα που βρίσκονται ως είσοδοι στα φύλλα. Το αποτέλεσμα βγαίνει από τη ρίζα.
Ακολουθεί η λύση:
- Κάθε φύλλο διαβάζει τα δεδομένα από την port A. Για πρακτικούς λόγους τα δεδομένα είναι τιμές των 2-bit. Μετά μεταδίδει αυτήν την τιμή στον μπαμπά του.
- Κάθε μία από τις ενδιάμεσες MCUs διαβάζει τις τιμές από το δεξί και το αριστερό παιδί της. Μετά αθροίζει τις τιμές αυτές και μεταδίδει το αποτέλεσμα στον μπαμπά της. (Αυτό μπορεί να γίνει για πολλά επίπεδα του δένδρου αν το δένδρο έχει περισσότερες MCUs.)
- Η ρίζα MCU εκτελεί όλες τις λειτουργίας μιας ενδιάμεσης MCU (εκτός από τη μετάδοση του αποτελέσματος) και ακόμη βγάζει το αποτέλεσμα στην portA (0,1,3,4). Σημειώστε ότι υπάρχουν 4 αριθμοί που αθροίζονται και κάθε ένας έχει εύρος 2-bits, άρα το αποτέλεσμα χρειάζεται 4-bits για πλήρη αναπαράσταση.
Ο κώδικας για αυτές τις τρεις περιπτώσεις (φύλλο, ενδιάμεσο, ρίζα) παρουσιάζεται στον επόμενο πίνακα:
;Root loop: ;================= ; read-write value AND W3,W4,W6 SL W3,#1,W7 AND W7,W5,W7 IOR W6,W7,W7 MOV W7,PORTA ;================= ; RxD --> RP15 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0F,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= NOP ;================= MOV #100,W8 loopW1: NOP DEC W8,W8 BRA NZ,loopW1 ;================= ; read left data (W1) MOV U1RXREG,W1 ;================= ; RxD --> RP13 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0D,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= NOP ;================= MOV #100,W8 loopW2: NOP DEC W8,W8 BRA NZ,loopW2 ;================= ; read right data (W2) MOV U1RXREG,W2 ;================= ADD W1,W2,W3 ;================= BRA loop |
;Middle L loop: ;================= ; read-write value NOP NOP NOP NOP NOP ;================= ; RxD --> RP15 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0F,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= MOV W3,U1TXREG ;================= MOV #100,W8 loopW1: NOP DEC W8,W8 BRA NZ,loopW1 ;================= ; read left data (W1) MOV U1RXREG,W1 ;================= ; RxD --> RP13 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0D,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= NOP ;================= MOV #100,W8 loopW2: NOP DEC W8,W8 BRA NZ,loopW2 ;================= ; read right data (W2) MOV U1RXREG,W2 ;================= ADD W1,W2,W3 ;================= BRA loop |
;Middle R loop: ;================= ; read-write value NOP NOP NOP NOP NOP ;================= ; RxD --> RP15 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0F,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= NOP ;================= MOV #100,W8 loopW1: NOP DEC W8,W8 BRA NZ,loopW1 ;================= ; read left data (W1) MOV U1RXREG,W1 ;================= ; RxD --> RP13 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0D,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= MOV W3,U1TXREG ;================= MOV #100,W8 loopW2: NOP DEC W8,W8 BRA NZ,loopW2 ;================= ; read right data (W2) MOV U1RXREG,W2 ;================= ADD W1,W2,W3 ;================= BRA loop |
;Leaf L loop: ;================= ; read-write value MOV PORTA,W1 AND W1,W4,W1 NOP NOP NOP ;================= ; RxD --> RP15 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0F,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= MOV W1,U1TXREG ;================= MOV #100,W8 loopW1: NOP DEC W8,W8 BRA NZ,loopW1 ;================= ; read left data (W1) NOP ;================= ; RxD --> RP13 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0D,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= NOP ;================= MOV #100,W8 loopW2: NOP DEC W8,W8 BRA NZ,loopW2 ;================= ; read right data (W2) NOP ;================= NOP ;================= BRA loop |
;Leaf R loop: ;================= ; read-write value MOV PORTA,W2 AND W2,W4,W2 NOP NOP NOP ;================= ; RxD --> RP15 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0F,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= NOP ;================= MOV #100,W8 loopW1: NOP DEC W8,W8 BRA NZ,loopW1 ;================= ; read left data (W1) NOP ;================= ; RxD --> RP13 MOV #0x0008,W6 MOV W6,U1MODE MOV #0x1F0D,W6 MOV W6,RPINR18 MOV #0x8008,W6 MOV W6,U1MODE MOV #0x04C0,W6 MOV W6,U1STA ;================= MOV W2,U1TXREG ;================= MOV #100,W8 loopW2: NOP DEC W8,W8 BRA NZ,loopW2 ;================= ; read right data (W2) NOP ;================= NOP ;================= BRA loop |
Πίνακας 2: Ο κώδικας για τον αλγόριθμο άθροισης σε δυαδικό δένδρο.
Η καθυστέρηση μεταξύ αποστολής και λήψης έχει ήδη συζητηθεί στον προηγούμενο αλγόριθμο.
Όλες οι MCUs έχουν τον ίδιο κώδικα αρχικοποίησης εκτός από την αρχικοποίηση της portA (Τα φύλλα χρειάζονται 2 bits είσοδο, ενώ η ρίζα απαιτεί 4-bit έξοδο).
Σε αυτόν τον αλγόριθμο κάθε MCU χρησιμοποιεί ένα (1) UART. Ο πομπός αντιστοιχίζεται στο RP11. Ο δέκτης συνδέεται πρώτα στο RP15 (ώστε να διαβαστεί η τιμή από το αριστερό παιδί) και έπειτα στο RP13 (ώστε να διαβαστεί η τιμή από το δεξί παιδί). Αυτό σημαίνει ότι η MCU στα αριστερά πρέπει να μεταδώσει την τιμή της στο πρώτο βήμα, ενώ η MCU στα δεξιά πρέπει να μεταδώσει την τιμή της στο δεύτερο βήμα. Αυτό φαίνεται στις στήλες L και R για τα φύλλα και τις ενδιάμεσες MCUs. Η διαφορά στον κώδικα στις L και R στήλες είναι στην στιγμή μετάδοσης των δεδομένων.
Το δίκτυο διασύνδεσης δημιουργείται συνδέοντας το RP11 από κάθε L - MCUs με το RP15 από τον αντίστοιχο μπαμπά, και το RP11 από κάθε R – MCUs με το RP13 του αντίστοιχου μπαμπά.
Οι γραμμές NOP εισάγονται για να κρατήσουν όλες τις MCUs σε συγχρονισμό.
Τα πρώτα δεδομένα που βγαίνουν από την PortA της MCU 7 δεν έχουν νόημα, καθώς αντιστοιχούν σε τιμές από μεταβλητές εσωτερικά των MCUs. Ο βρόγχος θα πρέπει να εκτελεστεί τρεις (3) φορές για να βγουν σωστά δεδομένα. Κάθε αλλαγή στα δεδομένα εισόδου θα φανεί στα δεδομένα εξόδου μετά από τρεις (3) εκτελέσεις του βρόγχου.
Ο κώδικας μπορεί να γραφεί και με άλλο τρόπο όπου χρησιμοποιούνται δύο (2) UARTs για την λήψη των δεδομένων. Με αυτόν τον τρόπο επιταχύνεται όλη η διαδικασία καθώς οι τιμές από τα δύο παιδιά του κάθε κόμβου λαμβάνονται ταυτόχρονα, και επιπλέον δεν χρειάζεται να γίνεται αλλαγή στην αντιστοίχηση των ακροδεκτών με την είσοδο του UART. Βέβαια σε πολλούς άλλους αλγόριθμους δεν είναι δυνατόν να αποφευχθεί η ανακατεύθυνση των ακροδεκτών καθώς μπορεί ο μικροελεγκτής να χρειάζεται να επικοινωνεί με τρεις (3) ή και παραπάνω άλλους μικροελεγκτές. Οπότε αυτό είναι ένα καλό παράδειγμα για το πώς μπορεί να γίνεται αυτή η ανακατεύθυνση.
Η φωτογραφία που ακολουθεί δείχνει τον παράλληλο υπολογιστή (στην έκδοση 1.0) με την τοπολογία του δένδρου και μια βοηθητική κάρτα με jumpers για είσοδο και leds για έξοδο.

Φωτογραφία 3: Ο παράλληλος υπολογιστής (V1.0) συνδεδεμένος ως δυαδικό δένδρο.
Το παράδειγμα βρίσκεται στο φάκελο “Treesum”. Το αρχείο “Treesum.s” κρατάει τον πηγαίο κώδικα σε assembly για την MCU 1. Κατά την μεταγλώττιση το παραγόμενο hex αρχείο πρέπει να μετονομαστεί χειροκίνητα (όπως στο προηγούμενο παράδειγμα). Τα αρχεία που προκύπτουν είναι: “Treesum_leaf_L.hex”, “Treesum_leaf_R.hex”, “Treesum_middle_L.hex”, “Treesum_middle_R.hex”, “Treesum_root.hex”.
5.3 Linear array – Ταξινόμηση.
Σε άλλη σελίδα παρουσιάζεται αλγόριθμος για ταξινόμηση σε ένα linear array (Ι/Ο σε κάθε μονάδα επεξεργασίας).
Ο κώδικας μπορεί να βελτιωθεί αν ο πομπός και ο δέκτης του UART χρησιμοποιούνται ταυτόχρονα. Με τον τρόπο αυτό όλες οι MCUs εκτελούν τη λειτουργία σύγκρισης και ανταλλαγής και δεν υπάρχει λόγος για δεύτερη αποστολή δεδομένων . Στον παρακάτω πίνακα δίνεται το τμήμα του κώδικα για την λύση αυτή (αν και δεν έχει δοκιμαστεί ακόμη!).
;Odd_L …. setup_RxD_RP12 ;================= ; send data MOV W1,U1TXREG ;================= wait ;================= ; receive data MOV U1RXREG,W2 ;================= ; compare-exchange CP W1,W2 BRA LE,labA MOV W2,W1 BRA labB labA: NOP NOP labB : ;================= NOP NOP NOP NOP NOP NOP NOP NOP ;================= ; send data NOP ;================= wait ;================= ; receive data NOP ;================= ; compare-exchange NOP NOP NOP NOP NOP ;================= DEC W7,W7 ….
|
;Odd_M …. setup_RxD_RP12 ;================= ; send data MOV W1,U1TXREG ;================= wait ;================= ; receive data MOV U1RXREG,W2 ;================= ; compare-exchange CP W1,W2 BRA LE,labA MOV W2,W1 BRA labB labA: NOP NOP labB : ;================= setup_RxD_RP14 ;================= ; send data MOV W1,U1TXREG ;================= wait ;================= ; receive data MOV U1RXREG,W2 ;================= ; compare-exchange CP W2,W1 BRA LE,labAA MOV W2,W1 BRA labBB labAA: NOP NOP labBB: ;================= DEC W7,W7 …. |
;Even_M …. setup_RxD_RP14 ;================= ; send data MOV W1,U1TXREG ;================= wait ;================= ; receive data MOV U1RXREG,W2 ;================= ; compare-exchange CP W2,W1 BRA LE,labA MOV W2,W1 BRA labB labA: NOP NOP labB : ;================= setup_RxD_RP12 ;================= ; send data MOV W1,U1TXREG ;================= wait ;================= ; receive data MOV U1RXREG,W2 ;================= ; compare-exchange CP W1,W2 BRA LE,labAA MOV W2,W1 BRA labBB labAA: NOP NOP labBB : ;================= DEC W7,W7 …. |
;Even_R …. setup_RxD_RP14 ;================= ; send data MOV W1,U1TXREG ;================= wait ;================= ; receive data MOV U1RXREG,W2 ;================= ; compare-exchange CP W2,W1 BRA LE,labA MOV W2,W1 BRA labB labA: NOP NOP labB : ;================= NOP NOP NOP NOP NOP NOP NOP NOP ;================= ; send data NOP ;================= wait ;================= ; receive data NOP ;================= ; compare-exchange NOP NOP NOP NOP NOP ;================= DEC W7,W7 …. |
Πίνακας 4: Εναλλακτική λύση για τον αλγόριθμο ταξινόμησης (μη ελεγμένο).
5.4 Linear array – φίλτρο FIR.
Οι αλγόριθμοι που παρουσιάστηκαν μέχρις εδώ έχουν καθαρά εκπαιδευτικό χαρακτήρα: κανένας δεν χρησιμοποιεί 8 MCUs για να αθροίσει 8 αριθμούς ή να ταξινομήσει 8 αριθμούς! Αυτοί οι εκπαιδευτικοί αλγόριθμοι δείχνουν ότι μια τυπική λύση σε κάθε πρόβλημα περιλαμβάνει βήματα επικοινωνίας που εναλλάσσονται με βήματα υπολογισμών. Στα προηγούμενα παραδείγματα τα βήματα επικοινωνίας είναι αργά (υπάρχει μια συνάρτηση καθυστέρησης ανάμεσα από κάθε εκπομπή και την αντίστοιχη λήψη). Αυτός ο ανενεργός χρόνος μπορεί να χρησιμοποιηθεί για υπολογισμούς!
Το παρόν παράδειγμα θα δείξει τη σχεδίαση ενός αλγορίθμου που μπορεί να είναι ταυτόχρονα και πρακτικός και αποδοτικός. Ο κώδικας δεν είναι πλήρης και δεν ελεγχθεί ακόμα.
Το "πρόβλημα" είναι να γίνουν οι υπολογισμοί ενός φίλτρου FIR (Finite Impulse Response). Αυτό περιγράφεται με την επόμενη εξίσωση:
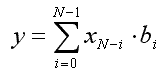
όπου το “y” είναι η τιμή εξόδου, τα “xi” είναι οι τιμές εισόδου, και τα “bi” είναι οι συντελεστές του φίλτρου.
Το δίκτυο διασύνδεσης για αυτόν τον αλγόριθμο είναι ένα linear array σε μία διάσταση όπως στο πρώτο παράδειγμα.
Ακολουθεί η λύση:
- Κάθε MCU κρατάει ένα σύνολο από συντελεστές και τις αντίστοιχες τιμές εισόδου. Για παράδειγμα, κάθε MCU μπορεί να κρατάει 64 συντελεστές, οδηγώντας σε ένα φίλτρο FIR με 8X64=512 συντελεστές.
- Κάθε MCU υπολογίζει το άθροισμα των γινομένων για τις τιμές που κρατάει.
- Κάθε MCU επικοινωνεί με την MCU στα δεξιά της για να στείλει το μερικό αποτέλεσμα και μια από τις τιμές εισόδου. Με τον τρόπο αυτό οι τιμές εισόδου "ταξιδεύουν" σε όλες τις MCUs.
- Κάθε MCU προσθέτει το μερικό άθροισμα που λαμβάνει από την MCU στα αριστερά με το εσωτερικό μερικό άθροισμα και μετά μεταδίδει το συνολικό άθροισμα προς τα δεξιά. (Η αριστερότερη MCU θεωρεί ως είσοδο το μηδέν και η δεξιότερη MCU δεν χρειάζεται να μεταδώσει τιμή δεδομένων εισόδου αλλά μόνο το αποτέλεσμα των αθροίσεων που είναι πια το τελικό αποτέλεσμα).
- Οι τιμές δεδομένων έχουν εύρος 16-bits και τα αθροίσματα έχουν εύρος 32 bits.
- Το εξωτερικό ρολόι είναι ένα πολλαπλάσιο του ρυθμού εισόδου/εξόδου (μπορεί να χρησιμοποιηθεί ένα PLL).
Ο χρόνος μεταξύ της αποστολής και της λήψης δεδομένων σε μια MCU μπορεί να χρησιμοποιηθεί για τους υπολογισμούς που δεν εξαρτώνται από τις λαμβανόμενες τιμές. Με αυτόν τον τρόπο ελαχιστοποιείται η επιβάρυνση από την επικοινωνία καθώς περιορίζεται στις εντολές που διαβάζουν και γράφουν τους καταχωρητές του UART. Φυσικά με 6 bytes επικοινωνίας σε κάθε εκτέλεση του βρόγχου, θα πρέπει να υπάρχει αρκετή δουλειά για τις MCUs για να τις κρατάει απασχολημένες κατά τη διάρκεια της επικοινωνίας. Αυτό σημαίνει ότι αυτό το παράλληλο φίλτρο θα είναι αποδοτικό μόνο όταν το μήκος του φίλτρου είναι μεγάλο. Αυτή είναι άλλωστε και η περίπτωση που απαιτεί τη χρήση μιας παράλληλης μηχανής!
6. Συμπεράσματα
Η παρούσα εργασία περιγράφει την υλοποίηση ενός παράλληλου υπολογιστή που χρησιμοποιεί τον μικροελεγκτή PIC24FJ16GA002-I/SP ως το βασικό στοιχείο επεξεργασίας. Οι μικροελεγκτές χρησιμοποιούν το εσωτερικό τους UARTs για να επικοινωνούν μεταξύ τους. Ο χρήστης δημιουργεί το δίκτυο διασύνδεσης ανάμεσα στους μικροελεγκτές. Το ειδικό χαρακτηριστικό "Peripheral Pin Select" των μικροελεγκτών χρησιμοποιείται για την δυναμική αντιστοίχιση των εισόδων και εξόδων των UARTs στους επιθυμητούς ακροδέκτες των μικροελεγκτών. Όλοι οι μικροελεγκτές εκτελούν τον κώδικά σε πλήρη συγχρονισμό.
Η παράλληλη μηχανή μπορεί να χρησιμοποιηθεί για εκπαιδευτικό σκοπό καθώς και για την επίλυση υπολογιστικά δύσκολων προβλημάτων που δεν μπορούν να λυθούν με έναν μόνο μικροελεγκτή. Η ανάπτυξη του απαιτούμενου προγράμματος δεν είναι μια εύκολη δουλειά καθώς οι παράλληλοι αλγόριθμοι είναι πιο πολύπλοκοι από τους απλούς αλγόριθμους. Η χρήση της παράλληλης μηχανής επιδεικνύεται μέσω μερικών παραδειγμάτων.
Ο πρωτότυπος υπολογιστής αποτελείται από οκτώ (8) μικροελεγκτές. Ωστόσο οι δυνατότητες επικοινωνίας επιτρέπουν την κατασκευή πολύ μεγαλύτερων μηχανών, για παράδειγμα μπορεί να κατασκευαστεί υπερκύβος με 4096 (=2^12) στοιχεία.
Το "κατέβασμα" του κώδικα στους μικροελεγκτές γίνεται μέσω ενός PC που εκτελεί ένα ειδικό πρόγραμμα που παρέχει και το απαραίτητο γραφικό περιβάλλον..
Αρχική σελίδα Παράλληλης Επεξεργασίας