Αρχική σελίδα Παράλληλης Επεξεργασίας
English version (Αγγλική έκδοση)
Ταξινόμηση σε Linear array
1) Θεωρητική παρουσίαση του αλγόριθμου
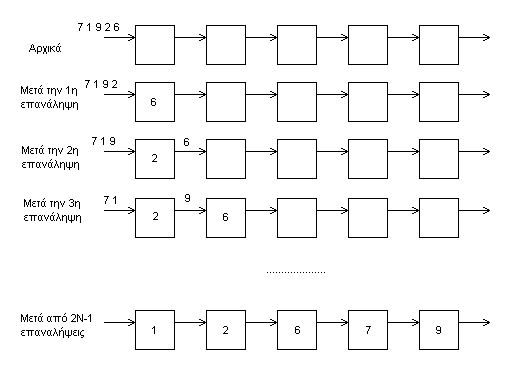
Ας θεωρήσουμε ότι έχουμε ένα linear array με Ν επεξεργαστικές μονάδες. Αποφασίζουμε ότι η είσοδος και η έξοδος των δεδομένων γίνεται μόνο στην πρώτη (1) και την τελευταία (Ν) επεξεργαστική μονάδα.(για άλλου είδους είσοδο-έξοδο υπάρχουν διαφορετικοί αλγόριθμοι).
Ο αλγόριθμος ταξινόμησης αποτελείται από δύο φάσεις. Στην πρώτη φάση γίνεται η εισαγωγή των δεδομένων και η ταξινόμηση, ενώ στη δεύτερη φάση τα ταξινομημένα στοιχεία βγαίνουν από το Linear array.
Κάθε επεξεργαστική μονάδα εκτελεί κατά την πρώτη φάση τις εξής ενέργειες:
α) λαμβάνει μία τιμή από τον αριστερό γείτονα.
β) συγκρίνει την τιμή που έλαβε με αυτήν που έχει αποθηκευμένη τοπικά.
γ) στέλνει την μεγαλύτερη από τις δύο τιμές στον δεξιό γείτονα.
δ) αντικαθιστά την τοπική τιμή με την μικρότερη από τις δύο τιμές.
Μετά από την επανάληψη των βημάτων αυτών 2Ν-1 φορές, οι τοπικές τιμές βρίσκονται ταξινομημένες κατά αύξουσα σειρά από την επεξεργαστική μονάδα 1 μέχρι την Ν. Το παρακάτω σχήμα δείχνει παραστατικά την διαδικασία.
Σημ. Τα δεδομένα που απεικονίζονται στις συνδέσεις μεταξύ των επεξεργαστικών μονάδων βρίσκονται στην πραγματικότητα σε καταχωρητές μέσα στις επεξεργαστικές μονάδες. Η είσοδος των δεδομένων γίνεται από την αριστερότερη μονάδα.
Στην δεύτερη φάση κάθε επεξεργαστική μονάδα εκτελεί τα παρακάτω βήματα:
α) λαμβάνει μία τιμή από τον δεξί γείτονα.
β) στέλνει την τοπικά αποθηκευμένη τιμή στην αριστερό γείτονα.
γ) αντικαθιστά την τοπική τιμή με αυτήν που έλαβε από δεξιά.
Με τον τρόπο αυτό τα δεδομένα βγαίνουν από την αριστερότερη επεξεργαστική μονάδα.
Περισσότερες λεπτομέρειες σχετικά με την ορθότητα και την απόδοση του αλγορίθμου βρίσκονται στο βιβλίο του F.T.Leighton.
2) Υλοποίηση
H υλοποίηση γίνεται σε "Parallel PIC" (Revision 1.0).
Η υλοποίηση γίνεται με πέντε (5) μονάδες επεξεργασίας (Μ.Ε.) που εργάζονται για την ταξινόμηση και δύο (2) μονάδες επεξεργασίας που λειτουργούν η μία για να παρέχει τα δεδομένα εισόδου και η άλλη για να παραλαμβάνει τα αποτελέσματα.
Ας ξεκινήσουμε με το πρόγραμμα που θα πρέπει να εκτελείται στις 5 κύριες Μ.Ε.
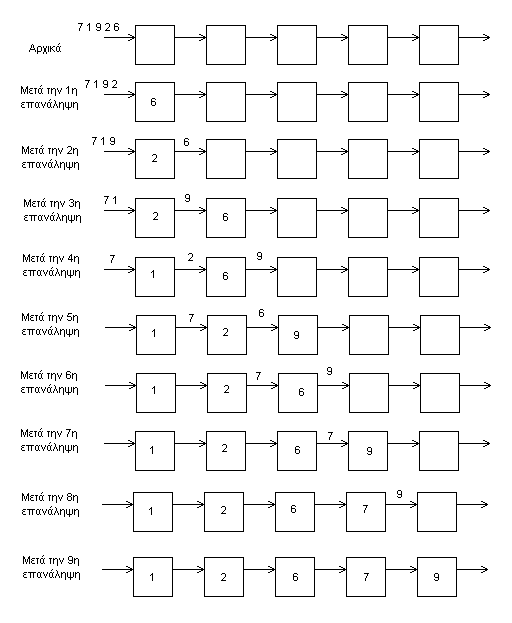
Το διάγραμμα που δείχνει την πορεία του αλγορίθμου φαίνεται ολοκληρωμένο στο επόμενο σχήμα:
Ο ψευδοκώδικας για την πρώτη φάση είναι:
|
For i = 1 to 9 /* N=5 ==> 2N-1 =9 */ read_data <-- RECEIVE(Left) if read_data > local_data then send_data <-- read_data local_data <-- local_data else send_data <-- local_data local_data <-- read_data endif SEND(Right) <-- send_data Next i |
Παρατηρώντας λίγο πιο προσεκτικά τον ψευδοκώδικα παρατηρούμε κατ' αρχήν ότι πρέπει να υπάρχει μια αρχική τιμή για την μεταβλητή "local_data". Στην περίπτωση που κάθε Μ.Ε. γνωρίζει την θέση του στο Linear Array μπορούμε να τροποποιήσουμε τον ψευδοκώδικα ώστε κάθε Μ.Ε. να "γνωρίζει" πότε αρχίζουν να έρχονται έγκυρα δεδομένα και να κάνει συγκρίσεις μόνο όταν πρέπει. Στην περίπτωση που οι Μ.Ε. δεν έχουν την πληροφορία της θέσης τους, μπορούμε να δεσμεύσουμε μία τιμή από το σύνολο τιμών που μπορούν να πάρουν τα δεδομένα και να αρχικοποιήσουμε την μεταβλητή "local_data" με την τιμή αυτή. Η τιμή πρέπει να είναι η μεγαλύτερη δυνατή ώστε να λειτουργεί η ταξινόμηση όπως περιγράφεται στα σχέδια. Βαφτίζουμε την τιμή αυτή ΜΑΧ. Το πρόγραμμα που έχει κατασκευαστεί χρησιμοποιεί την δεύτερη μέθοδο.
Λαμβάνοντας υπ' όψιν μας το θέμα του συγχρονισμού της επικοινωνίας θα πρέπει να τροποποιήσουμε τον αλγόριθμο ώστε τα SEND και RECEIVE να είναι μαζί, και μάλιστα πρώτα το SEND και μετά το RECEIVE. Αυτό οδηγεί στον παρακάτω αλγόριθμο:
|
send_data <-- MΑΧ local_data <-- MΑΧ For i = 1 to 9 /* N=5 ==> 2N-1 =9 */ SEND(Right) <-- send_data read_data <-- RECEIVE(Left) if read_data > local_data then send_data <-- read_data local_data <-- local_data else send_data <-- local_data local_data <-- read_data endif Next i |
Αν θελήσουμε να κάνουμε το σχηματικό διάγραμμα της εκτέλεσης του αλγόριθμου βγαίνει το παρακάτω σχήμα:

Παρατηρούμε ότι πλέον δεν μένουν δεδομένα ανάμεσα στις μονάδες επεξεργασίας μετά από κάθε βήμα. Αυτό συνέβαινε στα προηγούμενα σχήματα γιατί κάθε επανάληψη τελείωνε με ένα SEND, ενώ τώρα πια όταν τελειώνει κάθε επανάληψη έχει εκτελεστεί και το RECEIVE. Στο σχήμα φαίνονται μέσα σε παρενθέσεις και οι τιμές των μεταβλητών "send_data".
Ο ψευδοκώδικας για τη δεύτερη φάση είναι:
|
For i = 1 to 5 /* N=5 */ send_data <-- local_data SEND(Right) <-- send_data read_data <-- RECEIVE(Left) local_data <-- read_data Next i |
Ο ψευδοκώδικας αυτός διαφέρει από την περιγραφή που δόθηκε αρχικά για τη δεύτερη φάση στο ότι τα δεδομένα ταξιδεύουν προς τα δεξιά και όχι προς τα αριστερά. Με τον τρόπο αυτό η επικοινωνία μεταξύ των μονάδων επεξεργασίας είναι μονόδρομη και όχι αμφίδρομη. Το αντίτιμο είναι ότι χρειάζεται μια επιπλέον μονάδα για να δεχθεί τα ταξινομημένα δεδομένα.
Η μονάδα επεξεργασίας που κρατάει τα αρχικά αταξινόμητα δεδομένα (την ονομάζουμε ΑΡΧΙΚΗ) εκτελεί τον παρακάτω ψευδοκώδικα:
|
For i = 1 to 5 /* N=5 */ send_data <-- A[i] SEND(Right) <-- send_data Next i For i = 1 to 4+5 /* 4 (= N-1) for the first phase, */ /* 5 (= N) for the second phase. */ send_data <-- MAX SEND(Right) <-- send_data Next i |
Η μονάδα επεξεργασίας που δέχεται τα ταξινομημένα δεδομένα (την ονομάζουμε ΤΕΛΙΚΗ) εκτελεί τον παρακάτω ψευδοκώδικα:
|
For i = 1 to 9 /* N=5 ==> 2N-1 =9 */ read_data <-- RECEIVE(Left) Next i For i = 1 to 5 /* N=5 */ read_data <-- RECEIVE(Left) B[i] <-- read_data Next i |
Μετά την εκτέλεση του κώδικα που έχει περιγραφεί μέχρι εδώ, όλες οι μονάδες εκτός από την ΤΕΛΙΚΗ μπαίνουν σε έναν ατέρμονα βρόγχο. Η ΤΕΛΙΚΗ μονάδα στέλνει τα αποτελέσματα στη σειριακή της θύρα με ρυθμό 9600 bauds, ώστε να μπορεί ένας οποιοσδήποτε υπολογιστής να τα λάβει και να τα απεικονίσει.
Ο τελικός κώδικας αποτελείται από τρία προγράμματα, ένα για την ΑΡΧΙΚΗ μονάδα, ένα για τις 5 ενδιάμεσες μονάδες επεξεργασίας και ένα για την ΤΕΛΙΚΗ μονάδα. Όπως έχει ήδη τονιστεί θα πρέπει η επικοινωνία μεταξύ των μονάδων επεξεργασίας να είναι απόλυτα συγχρονισμένη. Η μέθοδος που ακολουθούμε, και που εφαρμόζεται και σε άλλους αλγορίθμους που υλοποιούνται στον parallelPIC, είναι να τοποθετήσουμε τα τρία διαφορετικά προγράμματα σε έναν πίνακα και να ελέγξουμε τον συγχρονισμό τους. Έτσι έχουμε:
|
For i = 1 to 5 send_d <-- A[i] SEND(R) <-- send_d Next i
For i = 1 to 4 send_d <-- MAX SEND(R) <-- send_d Next i
For i = 1 to 5 send_d <-- MAX SEND(R) <-- send_d
Next i |
send_d <-- MΑΧ local_d <-- MΑΧ For i = 1 to 9
SEND(R)<--send_d read_d<--ΡECEIVE(L) if read_d > local_d then send_d <-- read_d local_d<-- local_d else send_d <-- local_d local_d <-- read_d endif Next i
For i = 1 to 5 send_d<-- local_d SEND(R) <-- send_d read_d <-- RECEIVE(L) local_d <-- read_d Next i |
For i = 1 to 9
read_d <-- RECEIVE(L)
Next i
For i = 1 to 5
read_d <-- RECEIVE(L) B[i] <-- read_d Next i |
Εδώ βλέπουμε ότι ενώ η δεύτερη με την τρίτη στήλη δείχνουν να συγχρονίζονται εύκολα, η πρώτη στήλη έχει μια διαφορά: ο βρόγχος για την πρώτη φάση είναι "σπασμένος" σε δύο βρόγχους. Για να μη σπάσουμε και τους βρόγχους στις άλλες δύο στήλες, θα πρέπει να δοθεί ιδιαίτερη προσοχή κατά την κατασκευή του κώδικα της πρώτης στήλης ώστε να μην χαθεί ο συγχρονισμός κατά την έξοδο από τον πρώτο βρόγχο και την είσοδο στον δεύτερο!
Στο αρχείο ParallelPIC_Sort_LA.zip βρίσκονται τα αρχεία με τον πηγαίο κώδικα, καθώς και τα .hex αρχεία για την πρώτη ΜΕ (*_F.hex), για τις 5 ενδιάμεσες (*_M.hex) και για την τελευταία (*_L.hex). Το αρχείο του πηγαίου κώδικα περιέχει τον κώδικα και για τις τρεις περιπτώσεις και χρειάζεται μετάφραση με διαφορετική τιμή στην εσωτερική παράμετρο "processor".
Οι επεξεργαστές χρησιμοποιούν το RP15 για έξοδο και το RP14 για είσοδο. (Ο τελευταίος επεξεργαστής χρησιμοποιεί το RP2 για έξοδο προς το PC. Στην πλακέτα έχει προστεθεί ένας connector, που δεν περιγράφεται στην αρχική σχεδίαση, για την επικοινωνία με το PC μέσω της RS232.)
Μια φωτογραφία με την πλακέτα βρίσκεται εδώ.
{kind=link}