Home page of Parallel Processing
Ελληνική έκδοση (Greek version)
Sorting on a Linear array
1) Algorithm
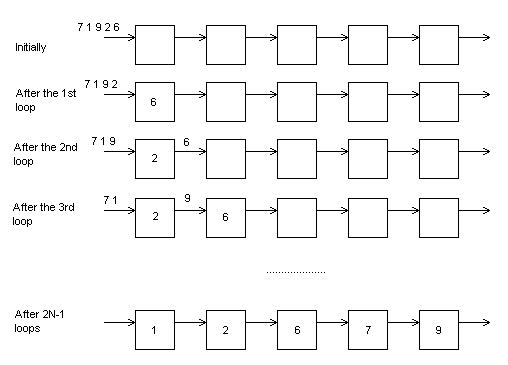
We have a linear array with Ν processing elements. We make the decision that the data input and output takes place only in the first (1) and the last (N) processing element (for other types of input-output there are other algorithms).
The sorting algorithm consists of two phases. In the first phase the data are fed into the machine and they are sorted. In the second phase the sorted data come out of the machine.
Each processing elements executes during the first phase the following operations:
i) receives one value from the left neighbor.
ii) compares the received value with the one that is locally stored.
iii) sends that greater of the two values to the right neighbor.
iv) replaces the local value with the smaller of the two values.
After the repetition of these steps for 2N-1 times, the local values become sorted in ascending order from processing element 1 to processing element N. The following figure shows this operation:
Note: the data that are shown onto the connections between the processing elements are implemented as local variables inside the processing elements. The data input come from the left-most unit.
During the first phase, each processing elements executes the following operations:
i) receives one value from the right neighbor.
ii) Sends the locally stored value to the left neighbor.
iii) replaces the locally stored value with the one acquired from the right neighbor.
This way, the data come out from the left-most processing element.
More details about the correctness and the efficiency of the algorithm can be found in the book of F.T.Leighton.
2) Implementation
The implementation is done in a "Parallel PIC" (Revision 1.0).
The implementation is done using five (5) processing elements (PEs) that work for the sorting and two (2) other PEs that are used one to supply the input data and the other to get the results.
Let us start with the program that is executed in the 5 main PEs.
The next diagram shows the complete flow of the algorithm:
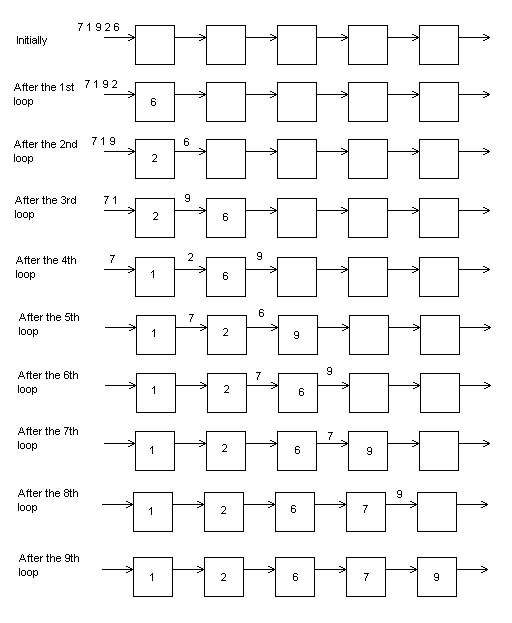
The pseudo-code for the first phase is:
|
For i = 1 to 9 /* N=5 ==> 2N-1 =9 */ read_data <-- RECEIVE(Left) if read_data > local_data then send_data <-- read_data local_data <-- local_data else send_data <-- local_data local_data <-- read_data endif SEND(Right) <-- send_data Next i |
This pseudo-code needs some modifications. In the first place, there must be an initial value for the variable "local_data". In the case where each PE knows its position inside the Linear Array, we can modify the code so that each PE knows when the received data are valid and so it can start the comparisons. In the case where the PEs do not have information of their position, we can reserve one value out of the set of legal values that data can take, and initiate the "local_data" variable with this value. This value must be the maximum possible so that the sorting operates as described in the figures. We call this value MAX. The program uses the second method.
Taking into account the aspect of communication synchronization we must modify the algorithm so that the SEND and RECEIVE be together, and especially first the SEND and second the RECEIVE. This leads to the next algorithm:
|
send_data <-- MΑΧ local_data <-- MΑΧ For i = 1 to 9 /* N=5 ==> 2N-1 =9 */ SEND(Right) <-- send_data read_data <-- RECEIVE(Left) if read_data > local_data then send_data <-- read_data local_data <-- local_data else send_data <-- local_data local_data <-- read_data endif Next i |
We can now make a detailed diagram to show the execution of the algorithm:
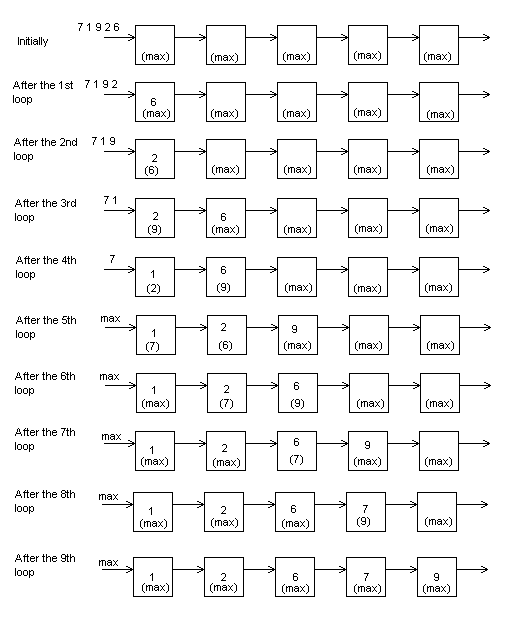
Note that there are no data between the processing elements after each step. This happened in the previous coding because each loop ended with a SEND command, while now each loop ends with a RECEIVE command. The figure shows also the values of the "send_data" variables inside parenthesis.
The pseudo-code for the second phase is:
|
For i = 1 to 5 /* N=5 */ send_data <-- local_data SEND(Right) <-- send_data read_data <-- RECEIVE(Left) local_data <-- read_data Next i |
This code differs from the initial description in the fact that the data travel toward the rightmost PE and not the leftmost PE. This way, the communication between the PES is one-way. The trade-off is the need for an additional processing element to get the data.
The processing element that keeps the initial non-sorted data (called FIRST) executes the following code:
|
For i = 1 to 5 /* N=5 */ send_data <-- A[i] SEND(Right) <-- send_data Next i For i = 1 to 4+5 /* 4 (= N-1) for the first phase, */ /* 5 (= N) for the second phase. */ send_data <-- MAX SEND(Right) <-- send_data Next i |
The PE that gets the sorted data (called FINAL) executes the following code:
|
For i = 1 to 9 /* N=5 ==> 2N-1 =9 */ read_data <-- RECEIVE(Left) Next i For i = 1 to 5 /* N=5 */ read_data <-- RECEIVE(Left) B[i] <-- read_data Next i |
After the execution of the so far described code, all PEs except the FINAL get into an endless loop. The FINAL unit transmits the data using a UART port with 9600 bauds. This way, any computer can get and display the results (for example a PC with a terminal program).
The final program consists of three (3) separate code parts: one for the FIRST unit, one for the 5 MIDDLE units and one for the LAST unit. As already mentioned, the communication between the units must be completely synchronized. The followed method (that is also used in other algorithms implemented into the ParalllePIC) is to put the three different code portions in a table and to check their synchronization "by hand". So we have:
|
For i = 1 to 5 send_d <-- A[i] SEND(R) <-- send_d Next i
For i = 1 to 4 send_d <-- MAX SEND(R) <-- send_d Next i
For i = 1 to 5 send_d <-- MAX SEND(R) <-- send_d
Next i |
send_d <-- MΑΧ local_d <-- MΑΧ For i = 1 to 9
SEND(R)<--send_d read_d<--ΡECEIVE(L) if read_d > local_d then send_d <-- read_d local_d<-- local_d else send_d <-- local_d local_d <-- read_d endif Next i
For i = 1 to 5 send_d<-- local_d SEND(R) <-- send_d read_d <-- RECEIVE(L) local_d <-- read_d Next i |
For i = 1 to 9
read_d <-- RECEIVE(L)
Next i
For i = 1 to 5
read_d <-- RECEIVE(L) B[i] <-- read_d Next i |
From the table we see that while the second and the third column seem to get synchronized easily, the first column has a main difference: the loop for the first phase is split into two loops. We do not want to split the respective loops in the other two columns (as it would be confusing), so there must be paid some attention in the construction of the loop in the first column in order to keep the synchronization during the transition between the first and the second loop.
File ParallelPIC_Sort_LA.zip keeps the source code as well as the .hex files for the FIRST PE (*_F.hex), the 5 MIDDLE PEs (*_M.hex) and the LAST PE (*_L.hex). The file with the source code contains the code for all three cases and needs compilation with different value in the internal parameter named "processor".
The MCUs use RP15 for output and RP14 for input. (The last MCU uses RP2 for output to the PC. The board has an additional connector (not described in the initial design) to communicate with the PC through RS232.
One picture of the board is given here.
{kind=link}